

Mysql底层详解-索引数据结构分析
索引的本质:索引是帮助Mysql高效获取数据的排好序的数据结构
本篇文章讲探讨如下问题:
1.Mysql索引在数据结构是怎样的?这种数据结构有什么特点?
2.聚集索引&非聚集索引&稀疏索引是什么
3. Mysql常用存储引擎索引实现
4.如何理解索引的顺序性
5.为什么InnoDB存储引擎中非主键索引结构叶子节点存储的是主键值?
一、Mysql索引数据结构及特点
常见的数据结构有二叉树、红黑树、Hash表、B-Tree、B+Tree,而MySQL索引底层是用的优化后的B+Tree(B+树)
MySQL为什么要用B+树而不用其他的数据结构呢,下面我们就来分析分析其他数据结构在存储数据上有什么弊端...
1.二叉树 & 二叉树搜索树
特点: 二叉树是一个树形结构,每个节点最多有两个子节点,子节点有且仅有一个父节点 ,二叉搜索树是在二叉树上的一个增强,对于树中的任意节点,其左子树上所有节点的值都小于该节点的值,而右子树上所有节点的值都大于该节点的值(左小右大)。
好处:二叉树搜索树这种树形结构是为了查找方便,查找时我们只需要比较查找目标与父节点的大小 如果大于走右边的子节点再进行比较,小于则走左边子节点进行比较....,如此往复,查找次数仅为遍历查找的一半,效率提升一半
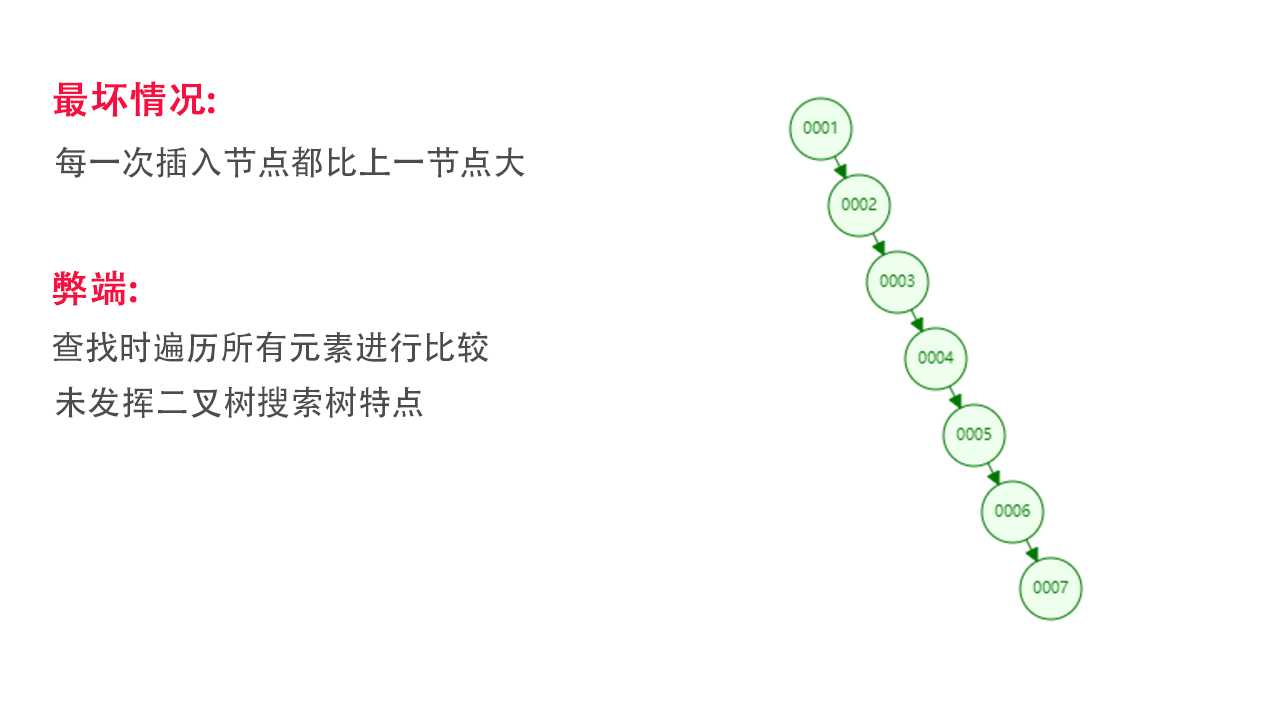
弊端:如上图,如果每一次插入都是比上一个数大,那么这种结构就会变成一个类似链表的形式 如下图,此时在查找是依旧需要每一个元素都要遍历比较,无法用到二叉搜索树的二分特点,查找效率等于全部遍历
2.红黑树
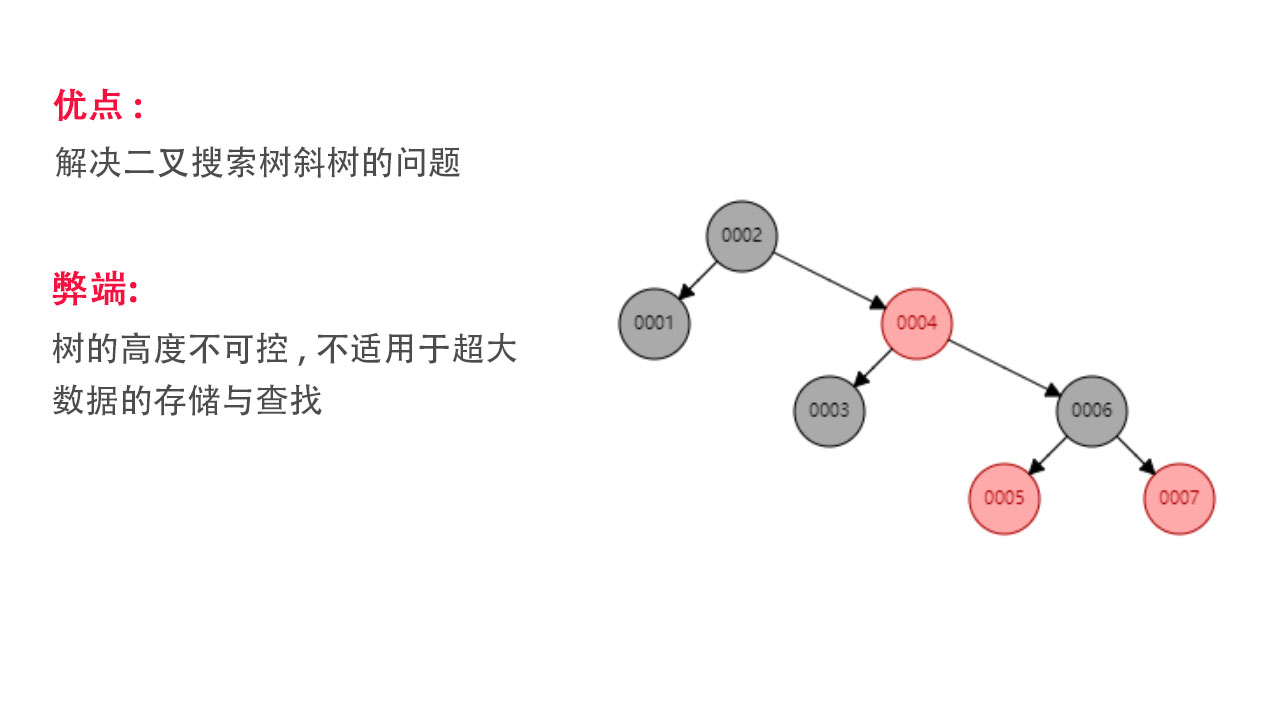
特点:红黑树是一种平衡二叉树,某种意义上说,他是二叉搜索树的一种增强,他可以利用自旋来解决平衡二叉树斜树的问题,提高搜索的效率
弊端:树的高度不可控,对于超大数据量的查找,还是显得比较慢,还有进一步优化的空间
3.B-Tree(B树)
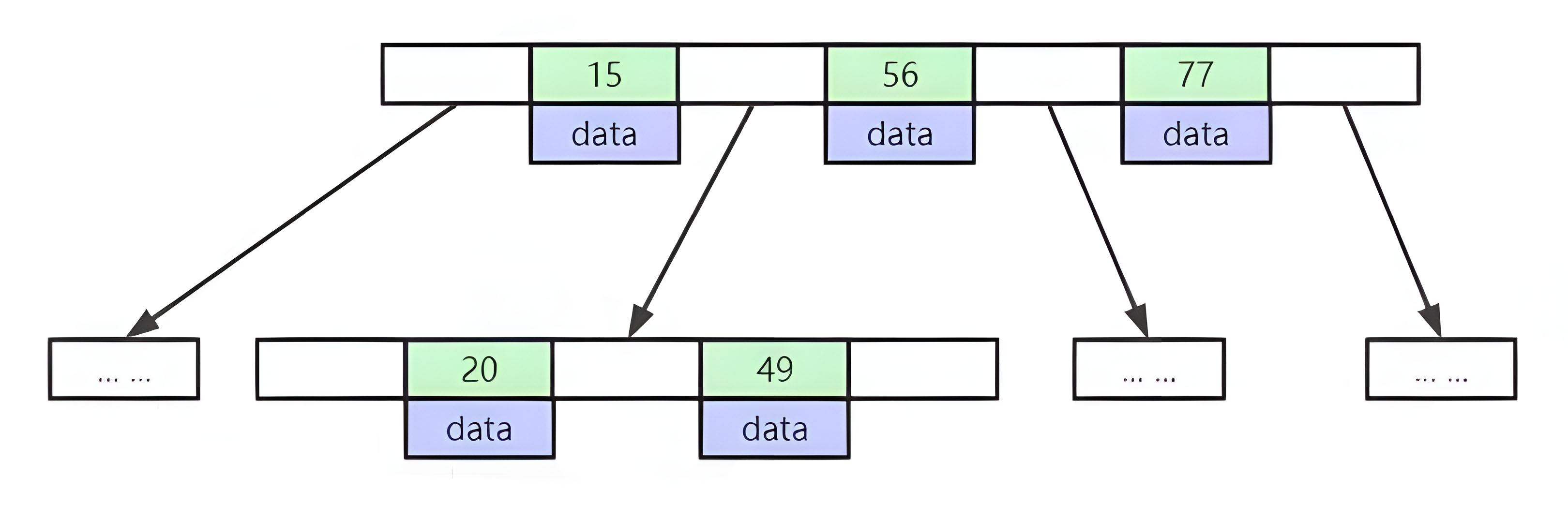
特点:B-Tree这种数据结构不是传统的树形结构,他将传统的树形结构做了一个增加,增加了树的宽度,来控制树的高度,一个大的节点存放多个小元素(每一个小的元素是一个KV),所有的节点都存在data,并且节点中的数据索引从左到右递增排列
提示:在Mysql中每一个节点就是一个页,每一页在磁盘上分配的空间大小大概是概16KB
可以利用如下SQL查看:show global status like 'Innodb_page_size'每一个节点由于是存储在磁盘上的,所以查找的节点越多与磁盘的IO交互越多
弊端:对于Mysql数据库而言,由于每一个元素存放了Data,在固定16Kb的情况下,导致每一页存放索引还不够多(还有优化空间)
4.B+Tree(B+树)
介绍:对于B树的增强,是mysql索引最终选择的数据结构(不同的存储引擎对于B+树的设计是不一样的),与B树相比,B+树所有在Data被存放到了叶子节点,非叶子节点全部存放索引,由于非叶子结点不存放Data,能够节省更多的空间来存储索引,所以B+树的一个节点上的索引面相比B树更多,那么在查找时能减少大量的磁盘IO交互,效率更高
特点:
①非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
②叶子节点包含所有索引字段
③叶子节点用指针连接,提高区间访问的性能
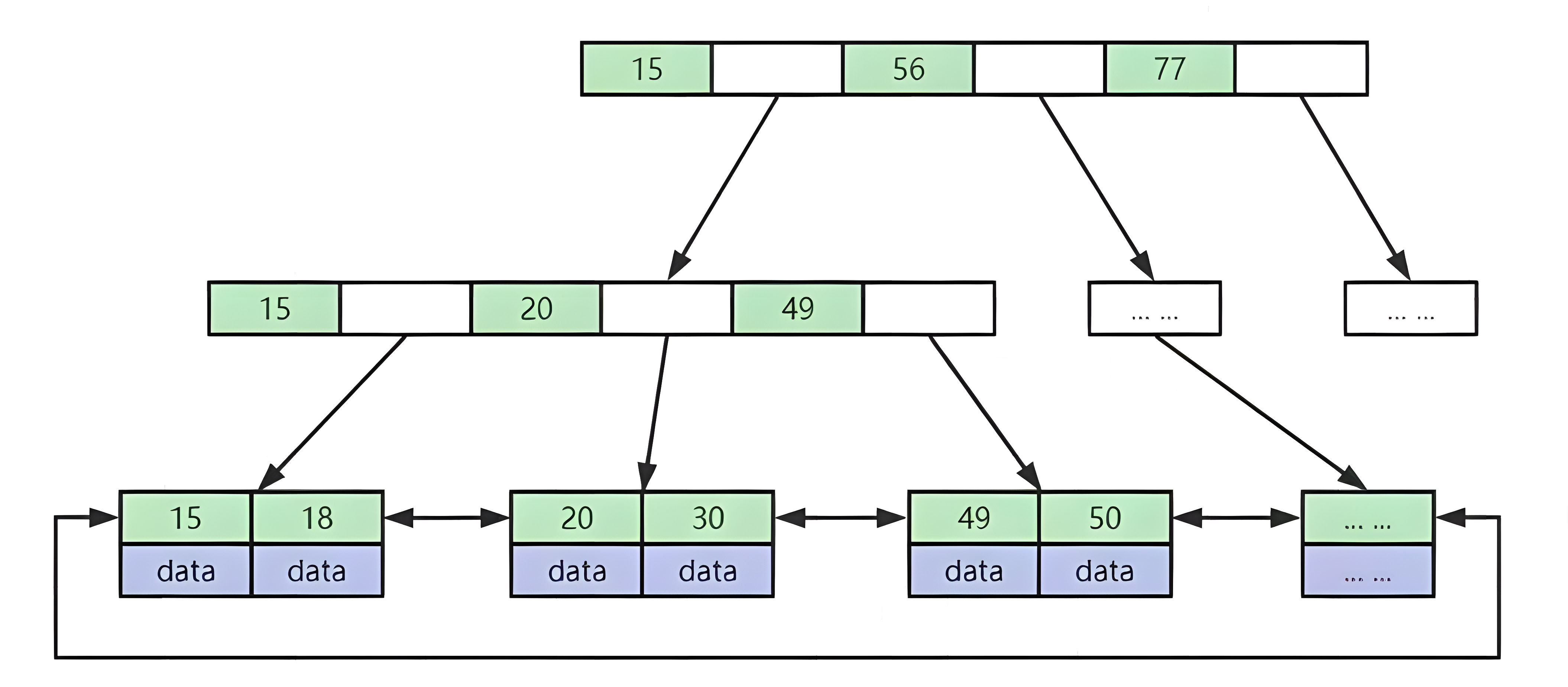
二、聚集索引 & 非聚集索引 是什么 以及Mysql常用存储引擎索引实现
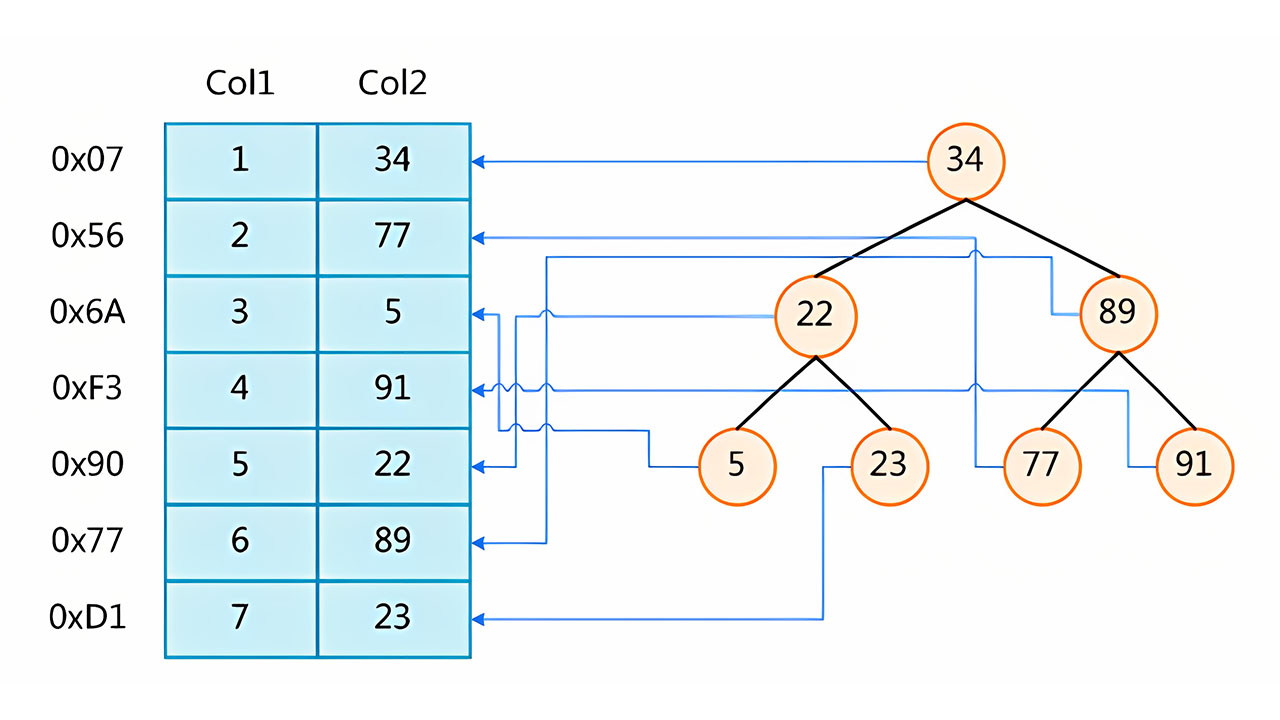
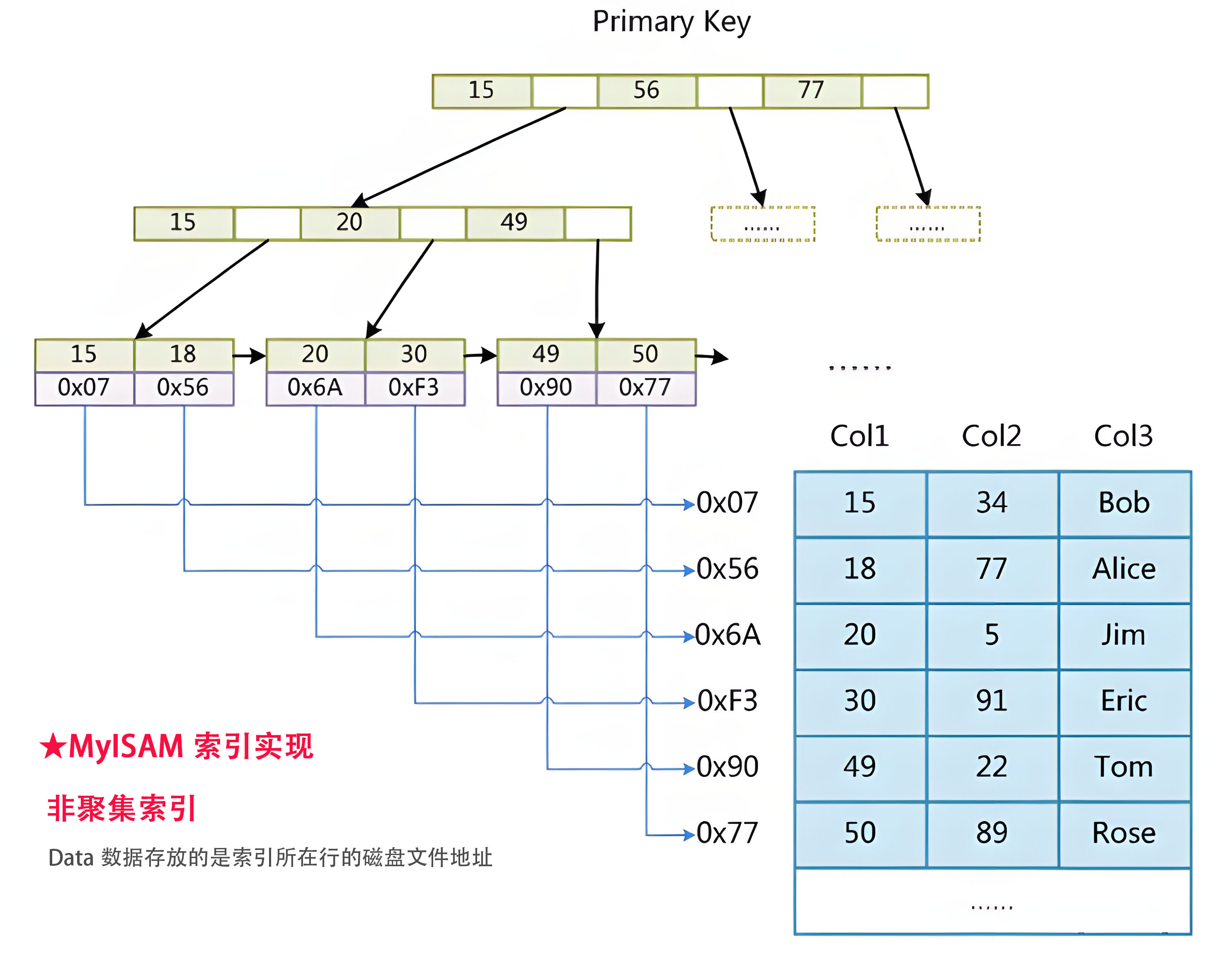
1.非聚集索引(MyISAM索引实现):索引和数据是分离的,如下图
为什么?因为MyISAM存储引擎创建索引时,会创建三个文件分别是
.frm(表结构文件)
.MYD(数据存放文件) -> MyISAM DB -->MYD
.MYI(索引文件)-> MyISAM Index -->MYI由于数据文件和索引文件不是一个文件,所以该索引B+树的叶子节点,存放的是数据所在行的磁盘文件地址,查找时会根据地址去MYD文件里面定位具体的数据行
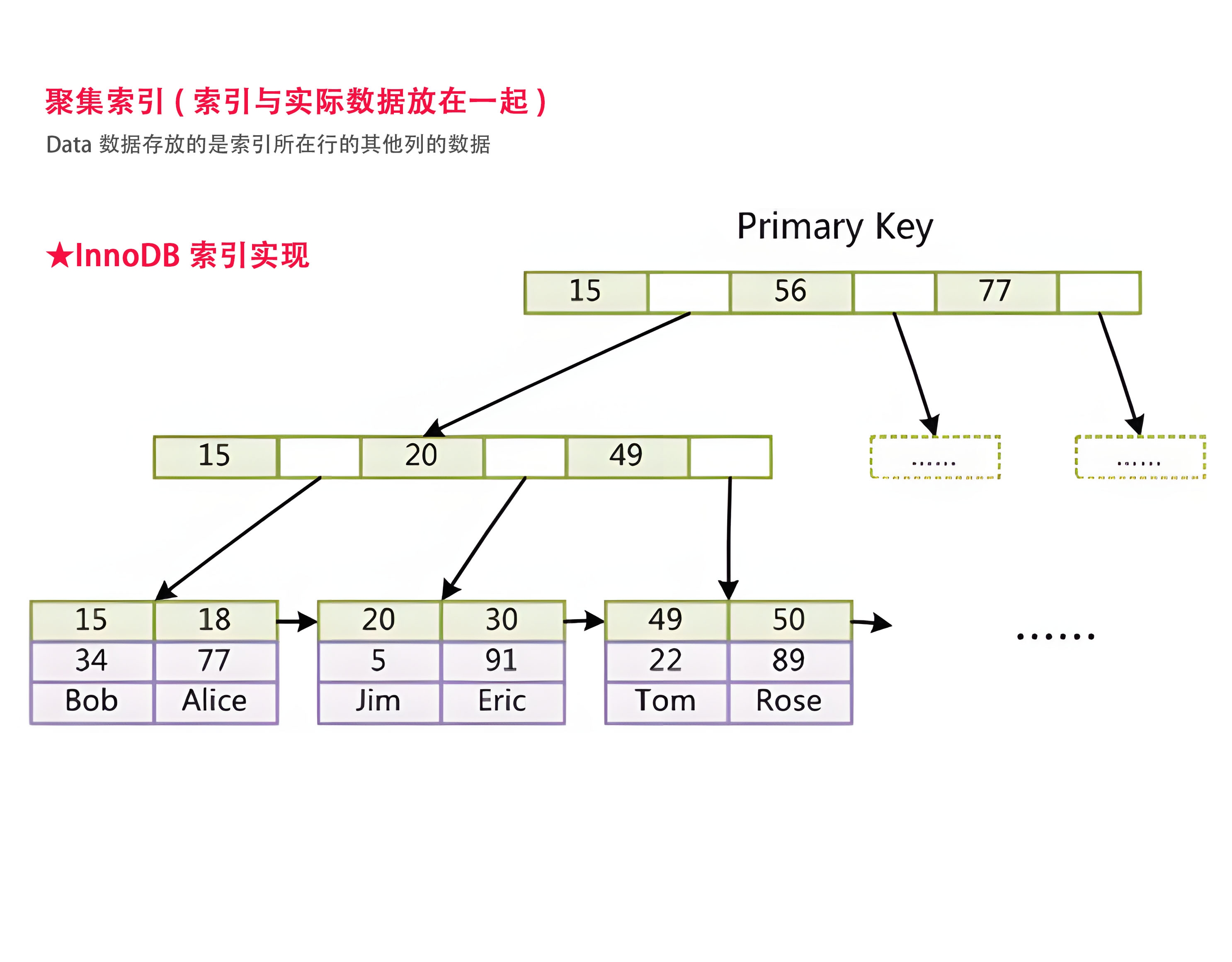
2.聚集索引(InnoDB索引实现):索引和数据是在一起的,如下图
为什么?InnoDB存储引擎创建索引时,会创建两个文件分别是
.frm(表结构文件)
.idb(存放索引以及数据)--该文件包含了这个表的所有数据,包括索引表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录★特点1:InnoDB存储引擎,创建索引时B+树的各个叶子节点是按照双向链表的形式进行链接的,他能够更好的支持范围查找
★特点2:非主键索引结构叶子节点存储的是主键值
三、如何理解索引的顺序性
为什么建议InnoDB表必须建主键,并且推荐使用整型约自增主建?
通过一、二的描述我们知道Mysql索引是用了B+树进行维护,而在B+树中叶子节点之间是保持一个顺序性的,也就是说每一次最好插入自增元素,如果将一个无序(非自增)的字段作为索引,那么每一次新增数据这棵B+树就要做额外的操作比如节点分裂、数据平衡等操作,这些操作会带来额外的性能消耗,所以尽量用自增字段做为索引字段。
四、为什么InnoDB存储引擎中非主键索引结构叶子节点存储的是主键值?
简答理解就是为了保证数据的一致性以及节省存储空间
InnoDB表只有一个聚集索引,这个聚集索引一般通过主键构建的,当你再去新建了一个其他索引字段的时候,这个新建索引Data指向的就是主键的值,Mysql会根据主键值去这个表的聚集索引里面找对应的数据,由此就能确保每一次当数据被修改后 查询数据的一致性,并且无论你对这个表新建多少个索引 ,Mysql只会根据当前索引字段生成对应的B+树,这棵树叶子节点的Data中只会存放主键,不需要吧这个表的所有字段全部存储到新的索引的Data中,节省了大量的空间

Richarditert
2024-02-13 15:23Your personal promotional code - "TWASIA24" on a private exchange www.cexasia.pro to receive 100USDT
对于我们交易所的首次注册,我们为您提供100usdt和30%首次存款的独特促销代码"pbasia24"!
欢迎和愉快的投标! [url=https://cexasia.pro/]Best asia bitchange[/url]